Balancing Model Performance
Fine-tuning is an iterative process where the goal is to find the "Goldilocks" zone: a model that has learned your specific data nuances without losing its ability to generalize. The fine-tuning process generates a number of metrics that can help you understand how well the model is performing. It's crucial to understand how to interpret the metrics and adjust the hyperparameters accordingly to achieve the best results. 2 common metrics that can help you identify the problem are:
- Training Loss: The average loss over the training dataset. It measures how well the model fits the data it is actively learning from, and you read it across the training run to see whether the model's error on familiar examples is decreasing. It matters because a training loss that keeps falling while other signals worsen is the clearest early warning that the model is memorizing the data rather than learning from it.
- Validation Loss: The average loss over the validation dataset, the data the model has never seen before. It measures how well the model generalizes beyond its training examples, and you compare it against training loss to judge whether learning is transferring to new inputs. It matters because validation loss is the metric that reveals overfitting: when it begins to climb while training loss continues to fall, the model is specializing too narrowly.
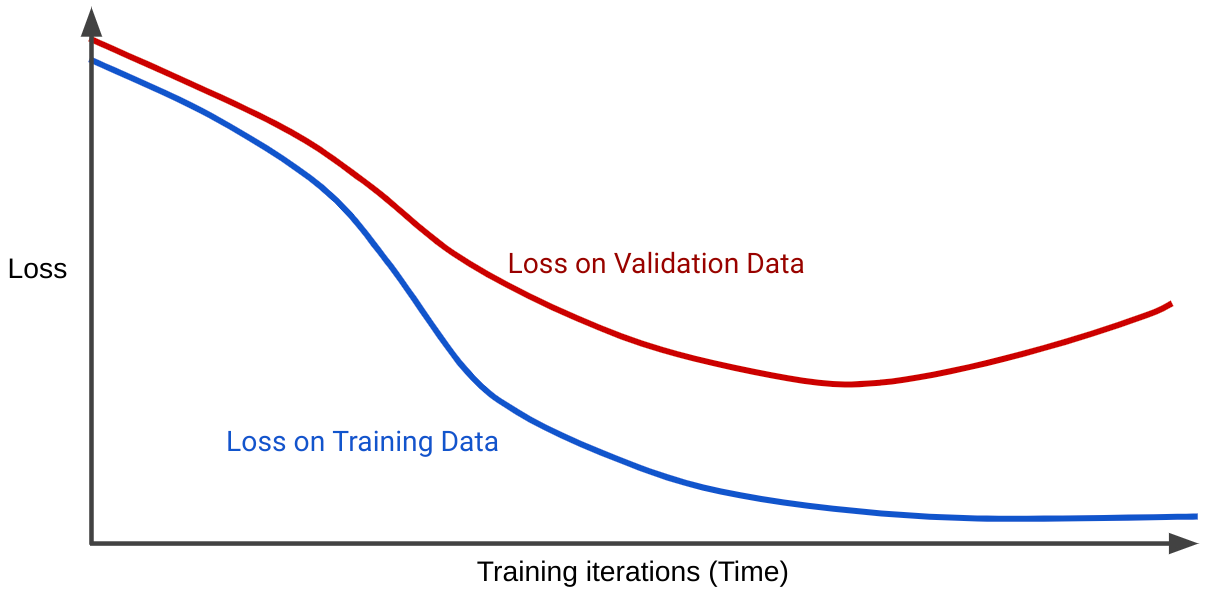
These metrics are often plotted against each other in
loss curvesto identify the problem. The loss curve shows how the model's error decreases over time. In a typical successful training run, you'll see a curve similar to the one below:
1. Overfitting (Too Specialized)
The Problem: The model effectively "memorizes" the training data, including its statistical noise. While training loss might look perfect, the model fails to perform on any data it hasn't seen before.
 Snapshot of Protean AI Platform
Snapshot of Protean AI PlatformIndicators
- Low Training Loss: If your training loss drops below 0.2, the model is likely overfitting.
- Validation Divergence: Training loss continues to go down, but evaluation/validation loss starts to climb.
Solutions
-
Inference Adjustments
-
LoRA Alpha Scaling: During inference, multiply the alpha value by 0.5. This scales down the impact of the fine-tune.
Note: We are working on a more efficient way to scale down the alpha using our interface.
-
-
Training Adjustments
-
Hyperparameter Adjustments:
- Reduce Epochs: Stick to 1 to 3 epochs for most fine-tuning tasks.
- Tune Learning Rate: A high learning rate can quickly lead to overfitting in short training runs. For longer training runs, higher learning rates may be effective. Test different values to determine what works best for your setup.
- Increase Regularization:
- Increase Weight Decay to 0.01 or 0.1 is a good starting point.
- Increase Lora Dropout, use 0.1 to add more regularization.
- Increase Effective Batch Size:
- Use larger batches or gradient accumulation steps to smooth out updates.
-
Early Stopping: Enable evaluation steps and stop training the moment evaluation loss increases for a consecutive number of steps.
Note: We are working to allow the user to configure this from our interface.
-
-
Data Adjustments:
- Use a larger dataset for more diverse data.
- Choose higher-quality datasets with more diverse data.
2. Underfitting (Too Generic)
The Problem: The model fails to capture the underlying patterns in your data. It remains too generic, often due to low training time, or poor data quality.
Indicators
-
High Loss: Both training and validation loss remain high and plateau quickly.
-
Lack of Adherence: The model fails to follow what it was specifically fine-tuned to do.
-
Training Adjustments
- Hyperparameter Adjustments:
- Increase Epochs: If the current rate is too low, increasing it may speed up convergence, especially for short training runs. For longer runs, try lowering the learning rate instead. Test both approaches to see which works best.
- Tune Learning Rate: A high learning rate can quickly lead to overfitting in short training runs. For longer training runs, higher learning rates may be effective. Test different values to determine what works best for your setup.
- Increase LoRA Rank & Alpha: Rank should at least equal to the alpha number, and rank should be bigger for smaller models/more complex datasets; it usually is between 4 and 64.
- Decrease Effective Batch Size: This will cause the model to update more vigorously.
- Hyperparameter Adjustments:
-
Data Adjustments:
- Domain Specific Data: Use a More Domain-Relevant Dataset.
Fine-tuning has no single "best" approach, only best practices. Experimentation is key to finding what works for your specific needs. Our recommended parameters give a great starting point.